Data Mining
What
- Data mining is the science of extracting useful information from large datasets.
How is Machine Learning different from Data Mining?
Machine learning is the process of TRAINING an algorithm on an EXISTING dataset in order to have it discover relationships (so as to create a model/pattern/trend), and USING the result to analyze NEW data.
Why
Some uses of data mining:
- predicting which customers will purchase what products and when
- deciding should insurance rates be set to ensure profitability
- predicting equipment failures, reducing unnecessary maintenance and increasing uptime to optimize asset performance
- anticipating resource demands
- predicting which customers are likely to leave and what can be done to retain them
- detecting fraud
- minimizing financial risk
- increasing response rates for marketing campaigns
How
Data mining algorithms: categories
- Classification: involves LABELING data
- Clustering: involves GROUPING data, based on similarity
- Regression: involves COUPLING data
- Rule extraction: involves RELATING data
另外还可以:
- 'supervised' learning method (where we need to provide categories for, ie. train, using known outcomes)
- 'unsupervised' method (where we provide just the data to the algorithm, leaving it to learn on its own).
1. Decision trees
What
Classification and regression trees (aka decision trees) are machine-learning methods for constructing prediction models from data. The models are obtained by recursively partitioning the data space and fitting a simple prediction model within each partition.
How
The decision tree algorithm works like this:
user provides a set of input (training) data, which consists of features (independent parameters) for each piece of data, AND an outcome (a 'label', ie. a class name)
the algorithm uses the data to build a 'decision tree' (binary tree, with feature-based conditionals at each non-leaf node), leading to the outcomes (known labels) at the terminals
the user makes use of the tree by providing it new data (just the feature values) - the algorithm uses the tree to 'classify' the new item into one of the known outcomes (classes)
Example: Should we play tennis?

Classification tree & Regression tree
- If the outcome (dependent, or 'target' or 'response' variable) consists of classes (ie. it is 'categorical'), the tree we build is called a classification tree.
- On the other hand if the target variable is continuous (a numeical quantity), we build a regression tree.
结果是分类为分类树,结果是数字为回归树
- Algorithms that create classification trees and regressions trees are known as CART(classification and regression tree) algorithms
2. k-means clustering
What
This algorithm creates 'k' number of "clusters" (sets, groups, aggregates..) from the input data, using some measure of closeness (items in a cluster are closer to each other than any other item in any other cluster).
This is an example of an unsupervised algorithm - we don't need to provide training/sample clusters, the algorithm comes up with them on its own.
How
- start with 'n' random locations ('centroids') in/near the dataset;
- assign each input point (our data) to the closest centroid; compute new centroids (from our data);
- iterate (till convergence is reached).
Example:
classify client,based on how many orders they placed, and what the orders cost

3. Support Vector Machine (SVM)
What
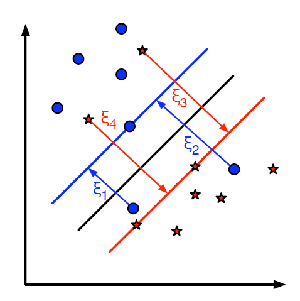
An SVM always partitions data (classifies) them into TWO sets - uses a 'slicing' hyperplane (multi-dimensional equivalent of a line), not a decision tree.
The hyperplane maximizes the gap on either side (between itself and features on either side). This is to minimize chances of mis-classifying new data.
The goal is to achieve "margin maximization"
How
On either side, the equidistant data points closest to the hyperplane are the 'support vectors'.
Special case - if there is a single support (closest point) on either side, in 2D, the separator is the perpendicular bisector of the line segment joining the supports; if not, the separating line/plane/hyperplane needs to be calculated by finding two parallel hyperplanes with no data in between them, and maximizing their gap.
通过support vectors找到能够区分两个类别的最理想(大)分界
- linearly separable data

- non-linearly separable data
4. A priori
what
Association analysis/Association rule learning
Looking for hidden relationships in large datasets.
The A priori algorithm comes up with association rules
example
Inputs:
- data
- size of the desired itemsets (eg. 2, 3, 4..),
- the support count (number of times the itemset occurs, divided by the total # of data items)
- the confidence (conditional probability of an item being in a datum, given another item).
**output:
- "items purchased together" (aka 'itemsets')

In the above, support for {soy milk,diapers} is 3/5; the confidence for {diapers} -> {wine} is support({diapers,wine})/support({diapers}), which is 3/5 over 4/5, which is 0.75.
- What is specified to the algorithm as input, is a (support,confidence) pair, and the algorithm outputs all matching associations - we would then make appropriate use of the results
5. kNN
- kNN (k Nearest Neighbors) algorithm picks 'k' neartest neighbors, closest to our unclassified (new) point, considers the 'k' neighbors' types (classes), and attempts to classify the unlabeled point using the neighbors' type data - majority wins
根据最近邻居点的类别来判定自己的类别
6. Hierarchical clustering
data

Hierarchical clustering

7. NN(Neural Nets)
What
A form of 'AI' - use neuron-like connected units that store learning (training) data that has known outcomes, use it to be able to gracefully respond to new situations (non-training, 'live' data) - like how humans/animals learn!
Usage
- recognize/classify features - traffic, terrorists, expressions, plants, words..
- detect anomalies - unusual CC activity, unusual machine states, gene sequences, brain waves..
predict exchange rates, 'likes'..
Neural nets are excellent for speech recognition tasks
8. EM(Expectation Maximization)
EM is an example of a family of EM is an example of a family of maximum likelihood estimator algorithms - others include gradient descent, and conjugate gradient algorithms.
9...Other
Ensemble Learning
Linear regression/Non-linear regression
Logistic regression
Naive Bayes
RandomForest(TM)
10. NN->Deep Learning
Why
Massive amounts of learnable data, massive storage, massive computing power, advances in ML
What revolution is happening right now related to this
- Medical Diagnosis
- Ribotics
- Automotive Safety
- Text&Speech Recognition